

Organizations prepare for everything from natural disasters to cyber-attacks with disaster recovery plans that detail a process to resume mission-critical functions quickly and without major losses in revenues or business operations.


Disasters come in all shapes and sizes. It’s not just catastrophic events such as hurricanes, earthquakes and tornadoes, but also incidents such as cyber-attacks, equipment failures and even terrorism that can be classified as disasters.
Companies and organizations prepare by creating disaster recovery plans that detail actions to take and processes to follow to resume mission-critical functions quickly and without major losses in revenues or business.
What is disaster recovery?
In the IT space, disaster recovery focuses on the IT systems that help support critical business functions. The term “business continuity” is often associated with disaster recovery, but the two terms aren’t completely interchangeable. Disaster recovery is a part of business continuity, which focuses more on keeping all aspects of a business running despite the disaster. Because IT systems these days are so critical to the success of the business, disaster recovery is a main pillar in the business continuity process.
The cost of disasters
Economic and operational losses can overwhelm unprepared businesses. One hour of downtime can cost small companies as much as $8,000, midsize companies up to $74,000, and large enterprises up to $700,000, according to a 2015 report from the IT Disaster Recovery Preparedness (DRP) Council.
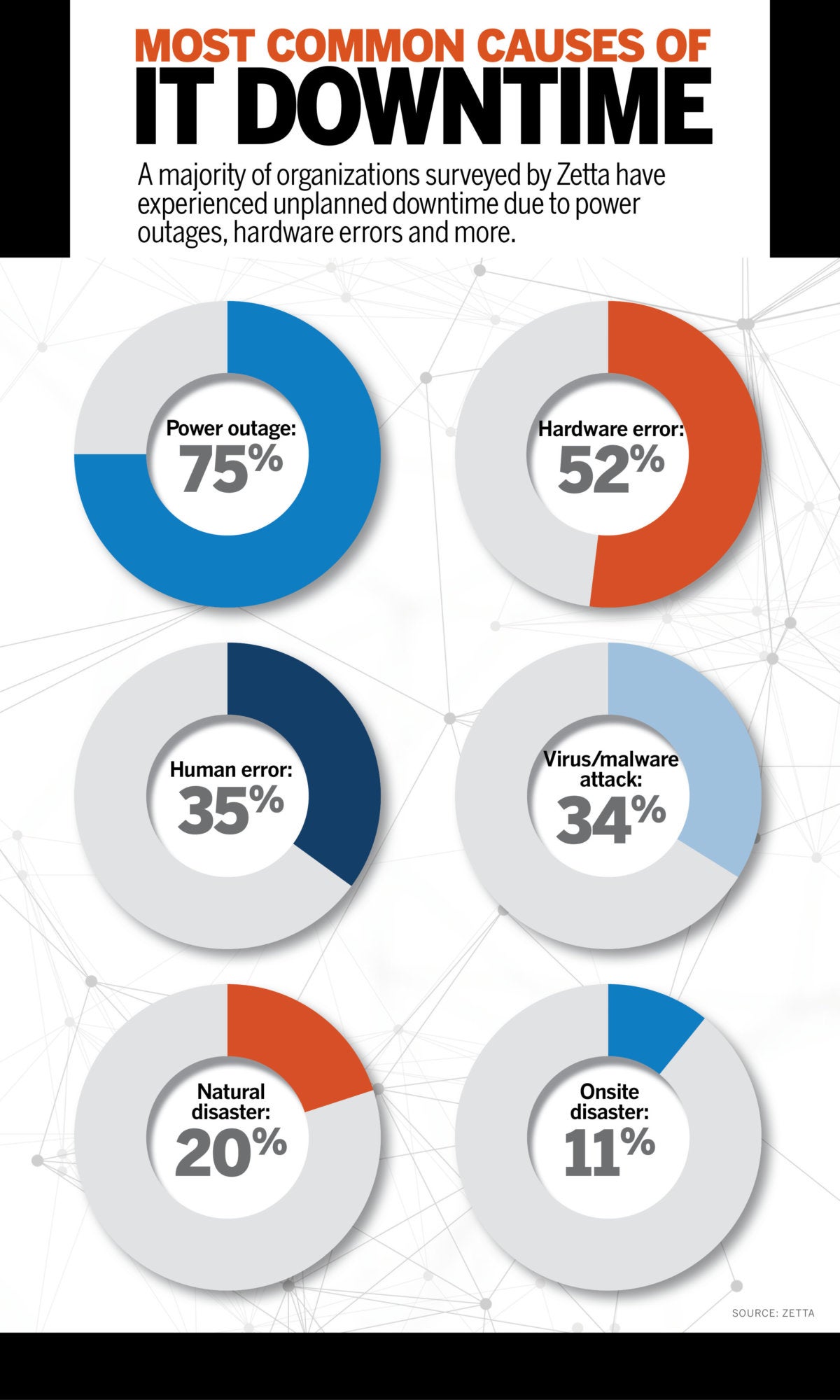
Another survey from disaster recovery service provider Zetta showed that more than half of companies surveyed (54%) had experienced a downtime event that lasted more than eight hours over the past five years. Two-thirds of those surveyed said their businesses would lose more than $20,000 for every day of downtime.
Risk assessments identify vulnerabilities
Even if your company already has a disaster recovery plan of some sort, it may be time for an update. If your company doesn’t have one, and if you’ve been handed the task of coming up with one, don’t jump in feet first without doing risk assessment. Identify vulnerabilities to your IT infrastructure and where things could go wrong. A prerequisite is knowing what your IT infrastructure looks like.
Knowing where things could go wrong doesn’t mean that you start creating worst-case scenario plans. In a recent blog post in the Disaster Recovery Journal, authors Tom Roepke and Steven Goldman suggest that naming the worst-case scenario in business continuity planning can be dangerous by drawing attention away from other significant threats:
“The natural tendency is to try to name or define what the worst case scenario is. This becomes a fatal flaw because it shapes the entire planning effort thereafter, even if it is at a subconscious level. So when we insert a named scenario – pandemic, earthquake, cyber-attack, etc., — we automatically start thinking and planning in terms of response/recovery for that specifically and subconsciously defined incident. When this occurs we not only tend toward a tunneled view in our planning efforts, but we are also in danger of increasing our risk and exposure. This is because there will be a hyper-focus on only one or two specific areas in what we think is the worst-case scenario, and not the actual event.”
Source: The ‘Worst Case Scenario’ Myth
The key, Roepke and Goldman suggest, is to focus on “managing the crisis, restoring business critical functions and recovering all while communicating with your stakeholders.”
What is a disaster recovery plan?
Type “disaster recovery plan template” into Google and dozens, if not hundreds, of templates will appear. Use those to get started and modify towards your business or organization.
The plan itself should include the following:
- Statement, overview and main goals of the plan.
- Contact information for key personnel and disaster recovery team members.
- Description of emergency response actions immediately following a disaster.
- Diagram of the entire IT network and the recovery site. Don’t forget to include directions on how to reach the recovery site for personnel that need to get there.
- Identifying the most critical IT assets and determining the maximum outage time. Get to know the terms Recovery Point Objective (RPO) and Recovery Time Objective (RTO). RPO indicates the maximum ‘age’ of files that an organization must recover from backup storage for normal operations to resume after a disaster. If you choose an RPO of five hours, then the system must back up at least every five hours. The RTO is the maximum amount of time, following a disaster, for the business to recover its files from backup storage and resume normal operations. If your RTO is three hours, it can’t be down longer.
- List of software, license keys and systems that will be used in the recovery effort.
- Technical documentation from vendors on recovery technology system software.
- Summary of insurance coverage.
- Proposals for dealing with financial and legal issues, as well as media outreach.
Building a disaster recovery team
The plan should be coordinated by IT team members responsible for critical IT infrastructure within the company. Others who need to be made aware of the plan include the CEO or a delegated senior manager, directors, department leaders, human resources and public relations officials.
Outsde the company, vendors associated with disaster recovery efforts (software and data backup, for example) and their contact information should be known. Facility owners, property managers, law enforcement contacts and emergency responders should also be known and listed within the plan (and updated frequently as names or phone numbers change).
Once the plan is written and approved by management, test the plan and update if necessary. Be sure to schedule the next review period and/or audit of the disaster recovery functions. Update, update, update as events transpire (large or small). Don’t just put the plan in a desk drawer and hope that a disaster doesn’t occur.
A disaster has happened – now what?
If a disaster has occurred, it’s time to start your incident response. Make sure that the incident response team (if it’s different from the disaster recovery planning team) has a copy of the disaster recovery plan.
Incident response involves assessing the situation (knowing what hardware, software, systems were affected by the disaster), recovery of the systems, and follow-up (what worked, what didn’t work, what can be improved).
What’s next? Cloud or recovery-as-a-service
Like many other enterprise IT systems that have moved to the cloud, so has disaster recovery. Benefits of the cloud include lower cost, easier deployment and the ability to test plans regularly. However, this could come with increased bandwidth needs or degrade a company’s network performance with more complex systems.
A 2016 Gartner report identified more than 250 providers of DRaaS offerings. Of course, you probably don’t want to review 250 companies and their offerings, so here’s a good place to start: Mike Smith, founder and president of AeroCom, and an IDG Network Contributor, offered up a report analyzing about 20 different DRaaS providers. Here’s another recent writeup of some top DRaaS companies to watch.
Analyst firm Forrester Research also has a take on the DRaaS market. It evaluated the 10 most significant players in the market in its Forrester Wave report (available for $2,500).

















