From firewalls to zero trust: How AI and next-gen cybersecurity are defining the future of digital protection. Learn more today.

A recent survey of cybersecurity professionals indicates that 81% of organizations are turning to zero trust as the foundation of their cybersecurity strategies. With growing concerns over advanced threats, VPN security issues, network complexity, and adversarial AI, enterprises are showing increased interest in a zero trust approach to security and moving away from firewall-and-VPN based architecture. This shift highlights the proactive measures businesses are taking to protect themselves from cyberthreats.
62% of organizations are planning to leverage AI in their cyber defenses, and more than half are planning to increase their security spending. The survey captured the current sentiments of IT and security professionals regarding the most serious cyberthreats they face, challenges with VPNs, security investment priorities, and the move to a zero trust security architecture. For more insights on how your peers are approaching cyber defense this year, download Zscaler State of Cyberthreats and Protection Report, which analyzes the results of a ViB survey commissioned by Zscaler.
Concerning cyberthreats
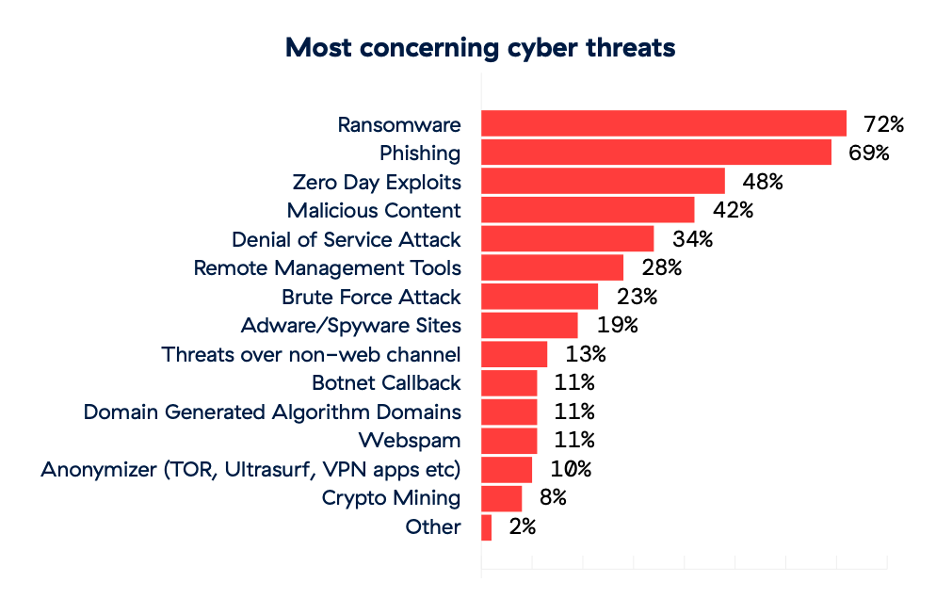
The past few years have seen an explosion in the number of cyberattacks, leaving businesses facing financial losses and significant damage to their brand reputations. Ransomware is certainly causing anxiety among security practitioners and was listed as a top cyberthreat concern by 72% of survey respondents. This is substantiated by Zscaler’s research wing, ThreatLabz, which determined that ransomware attacks will become more advanced and persistent. Zscaler ThreatLabz 2024 Ransomware Report disclosed a record-breaking ransom payment of $75 million to Dark Angles, a ransomware group, last year.
Phishing (69%) and zero-day exploits (48%) were also among the top concerns. The Zscaler ThreatLabz team observed that phishing threats have reached unprecedented levels of sophistication in the past year, driven by the proliferation of generative AI tools. These advancements are transforming how cybercriminals operate, revolutionizing and reshaping the phishing threat landscape.
Zscaler
This increase in cyberthreats is not just a matter of quantity; it reflects a dynamic and increasingly sophisticated landscape in which attackers are constantly improving their methods to outpace even the most well-defended networks.
In fact, the traditional VPN-based architecture emerged as a major point of risk in 2024, with many VPN vulnerabilities being exploited repeatedly. The repeated zero-day attacks on VPNs show that the real issue is the outdated architecture, not the specific vendors involved in these incidents. Survey responses reflected this ominous reality, with one in four respondents planning to move away from a VPN-based architecture.
Adversarial AI compromising security defenses
AI has evolved beyond just a groundbreaking innovation—it is now an integral part of everyday business operations, becoming deeply embedded in the core of enterprise activities. However, the questions surrounding the secure adoption of these AI tools and the defense against AI-driven threats remain unresolved.
Cybercriminals are progressively employing sophisticated artificial intelligence methods to circumvent traditional security protocols, engineering meticulously targeted and intricate attacks that capitalize on vulnerabilities within security frameworks.
Security teams are definitely paying attention. Over 95% of survey respondents are concerned about adversarial AI’s ability to evade known cybersecurity defenses.

Zscaler
The deployment of adversarial AI in cyberattacks is a burgeoning menace that organizations must acknowledge and prepare to confront. As AI technologies continue to advance in accessibility and potency, the complexity and scope of adversarial assaults are poised to escalate. While AI threatens to overwhelm security teams with the pace and sophistication of its onslaught, it can also enable proactive prevention. Fighting AI with AI will be the path forward.
Leveraging AI in security
On the other hand, AI is empowering security teams as well. AI is transforming security, providing unparalleled capabilities to identify, thwart, and address threats with rapidity and accuracy. In a time when cyberthreats are growing in complexity and agility, AI’s capacity for real-time surveillance and swift reaction is invaluable. By scrutinizing extensive data and revealing nuanced patterns that could evade conventional security protocols, AI empowers organizations to maintain a proactive stance and fortify their defense strategies.
Sixty-two percent of the survey respondents said that they plan to leverage AI capabilities in their cyber defenses within the next two years. Zero trust and smart vulnerability management can help prevent attacks by proactively reducing the attack surface and lowering real risk.

Zscaler
The state of Zero Trust
Zero trust, a cybersecurity strategy wherein least-privilege access controls, microsegmentation, and strict user authentication help to minimize risk, is gaining traction with the companies covered in the survey. When asked, “Do you take a zero trust approach to security in your organization?”, a total of 81% of respondents stated that they are either in the process of rolling out a zero trust strategy, are planning to do so this year, or already have zero trust tools and strategies deployed. This high level of interest may be due to the fact that a well-tuned zero trust architecture leads to simpler network infrastructure, a better user experience, and improved cyberthreat defense. Only 15% do not have a plan to embrace zero trust this year.
Prospective buyers of zero trust solutions have several selection criteria in mind. For 56%, price is the most important factor, followed by robustness (54%) and integration with existing security solutions (53%). Ease of use and scalability also matter, as do a proven presence in a particular industry and the breadth of the platform. If you have more questions about zero trust or key elements to implement it successfully, take a look at the Seven Questions Every CxO Must Ask about Zero Trust ebook.

Zscaler
The road ahead
Enterprises are increasingly aware of the need to enhance and streamline their cybersecurity efforts in response to the growing number and sophistication of cyberthreats. VPN- and firewall-centric approaches are not effective for reasons ranging from scale limitations to complex administration, to their vulnerability to exploits.
Zero trust is anticipated to be a defining trend in the cybersecurity landscape by 2025. This proactive orientation is not merely a response to present challenges; it stands as a strategic investment in readiness for the evolving threats of the future.
The AI-powered Zscaler Zero Trust Exchange™ provides comprehensive zero trust cyberthreat protection at the speed and scale of the cloud. Built on the principle of least privilege, our proxy architecture minimizes attack surface, prevents compromise, eliminates lateral movement, and stops data loss.
For the full report insights, download your copy of the Zscaler State of Cyberthreats and Protection Report today.








